
Web APIs are everywhere and, as developers, we generally spend a great deal of time building and updating them. While the most common implementations are REST APIs, there are alternatives that you might not have experimented with. The purpose of this article is to introduce one of those alternatives, GraphQL.
What is GraphQL?
GraphQL is an open-source data query and manipulation language paired with a cross-platform server-side runtime that provides a foundation for scalable and efficient communication for web applications. Despite its name, it is not a replacement for database systems. Instead, it provides a system for web clients to request or manipulate API data by specifying the objects and fields needed, while the server-side runtime interfaces with the database.
Is it like a REST API?
There are similarities between REST and GraphQL. Both cover machine-to-machine communication, most often between a web app client and a backend server. Both often use JSON to communicate information in requests. However their capabilities and goals are different. GraphQL behaves like a queryable hierarchical, strongly typed data model. REST is a looser and more general set of principles for web API design. GraphQL is an application-layer protocol powered by a server side engine, while REST specifies an architectural style.
Let’s consider a scenario where we want to fetch a blog writer’s name, the title of all the posts they’ve written, and the name of their last three followers.
A REST API receives requests and sends responses over the HTTP protocol. It uses HTTP methods – like GET, POST, PUT and DELETE – with URL patterns and parameters to indicate an action. Only one step can be executed per request, and the data returned is typically in a fixed format. A typical REST API would require the following steps to retrieve the data needed.
It takes three requests to get the desired data, and there are unnecessary data elements. Let’s talk through this a bit.
The request to /users/<id> gives us some basic information about the user but doesn’t give everything needed. This scenario is called under fetching and forces the client to make additional calls elsewhere to get the required data.
What if we have a list of users and need the same information for each user? We’d need to call the /users/<id>/posts and /users/<id>/followers endpoints for each user record. This scenario is the n+1 problem and can quickly get out of hand as the user list grows.
What about all the unnecessary data returned by each of the three endpoints? This scenario is called over fetching, which causes increased data size and impacts the cost and perceived performance.
How can we solve these issues? We could create REST endpoints for each use case – this is a reactive approach and could be challenging to scale to customer demand. Let’s look at how GraphQL solves these issues.
While GraphQL also receives requests and sends data over the HTTP protocol, it uses a limited range of HTTP methods – like GET or POST – and the client can request one or more actions or relationships from a single request endpoint. The request payload specifies the exact data needed, and the returned data is always in a JSON format. An equivalent GraphQL flow for the REST API user example would look like this.
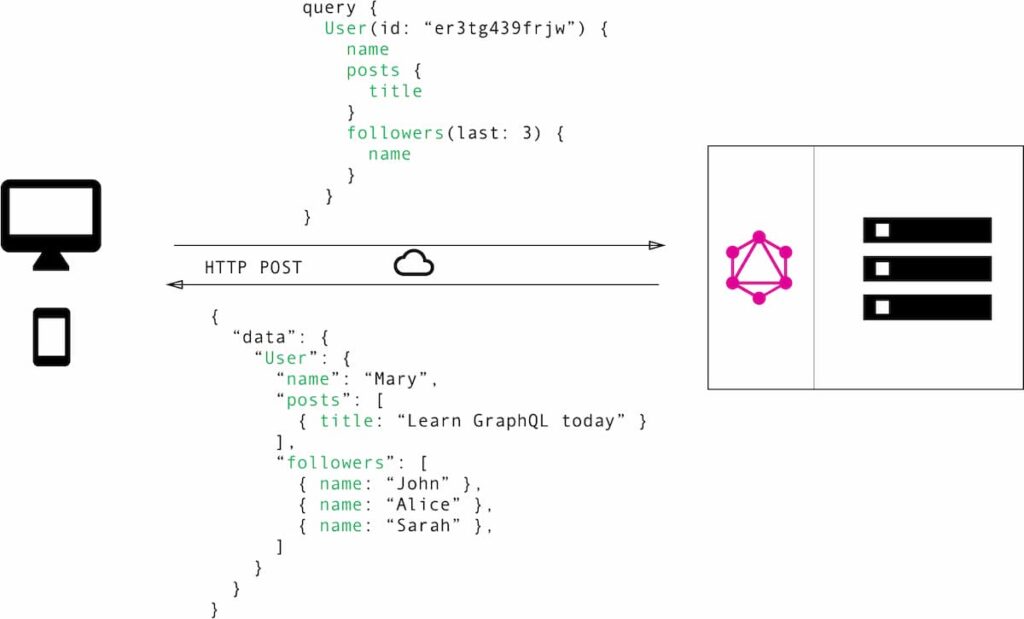
This is an efficient approach: the client defines what’s needed, makes one request to get all the data required, and the server returns only the data requested.
Again, while there are similarities between REST API and GraphQL, the capabilities are very different.
Let’s explore this more in the next section.
Contracts and Type Safety with GraphQL Schemas
A major problem with JSON-based services is the lack of a strict built-in contract regarding what the client can expect and the exact data type for each object or property.
Contracts in most JSON-based REST APIs consist of documentation and team communication, which aren’t runtime guarantees. This approach to contracts can be subject to miscommunication and have no automated validation to ensure adherence.
JSON is also limited by the amount of native data types – strings, numbers, booleans, arrays, general objects, and null – and cannot be extended to provide additional universal type-checked data types.
GraphQL solves these problems by using an extensible and strong type-based schema to define the capabilities of the API. Schemas are defined using the Schema Definition Language (SDL). SDL has a straightforward syntax and allows for a concise schema. A GraphQL endpoint’s schema is available to both the server and the client, and each request and response is validated before requesting or sending data.
A GraphQL schema for our blog writers example might look like this:

There’s a lot to unpack in this example. While it only scratches the surface, the main points here are:
- The
type Queryis a particular type of object. The Query object contains all the top-level entry points for querying data – likegetUser(id: ID!). - SDL allows for adding comments in-line to explain their behavior or usage. While my example shows a comment for the
getUser(id: ID!)entry point, you can add comments anywhere. - Entry points can take parameters and return data. The parameters and returned data always have data types.
- The other types –
User,Post,Address, andPostComments– define the service’s objects. Each object lists the fields, and each field is associated with a data type. - SDL defines some base of data types – like
IDandString– called scalars. You can define custom scalar types. I’ve created the custom scalar typesISO8601DateandISO8601DateTimeto indicate these types have a particular format. - An entry point or field can return an array of values, denoted as
[]. - The presence of the “
!“ character means that the field or the return value will not be null. - Object fields can have arguments – like
followers(last: Int)– allowing clients to filter or limit subfields.
Each GraphQL service has only one schema, and that schema defines the actions, objects, relationships, and data types the client should expect.
What about object and data reuse?
You may want to reference a service’s objects outside a single service; the User object is a great example. One possible solution is duplicating all the user data between GraphQL services, but that approach introduces tight coupling and adds complexity. Using a distributed GraphQL architecture to combine multiple GraphQL schemas, there’s no need to duplicate user data or introduce tight coupling. Let’s look at how this works in the next section.
Combining Multiple GraphQL Schemas
You could create one monolithic application instead of juggling numerous GraphQL services. This approach eliminates needing to combine various schemas; however, your use case may require a microservice approach to scale specific components of your system or allow for the separation of concerns design principle.
For the latter, we’ll look at the Apollo Federation (federation) distributed GraphQL architecture.
There are many distributed GraphQL architectures and techniques to accomplish this feat – schema merging, schema stitching, schema wrapping, and federation. I’ll focus on the federation approach for this article since it fits the needs of my example.
Federation introduces a gateway – called a supergraph gateway – that combines multiple GraphQL service schemas into a unified graph, or supergraph. Each GraphQL service registered with the supergraph gateway is called a subgraph service, and each subgraph service’s schema is combined into a supergraph served by the supergraph gateway. Clients interact with the supergraph gateway, and the supergraph gateway routes requests to the appropriate subgraph service.
Let’s split our blog writers schema example into two subgraphs – a Users subgraph that handles User and Address and a Posts subgraph that handles Post and PostComment. We want the web clients to interact with the supergraph gateway, and the supergraph gateway will forward requests to the relevant subgraph once they are registered.
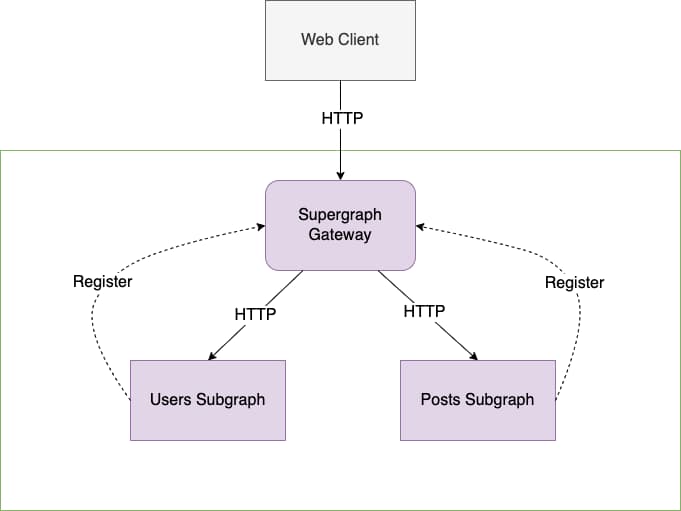
This approach enables a lot of flexibility with architecture design. Let’s look at how our original GraphQL schema could be split up per microservice.
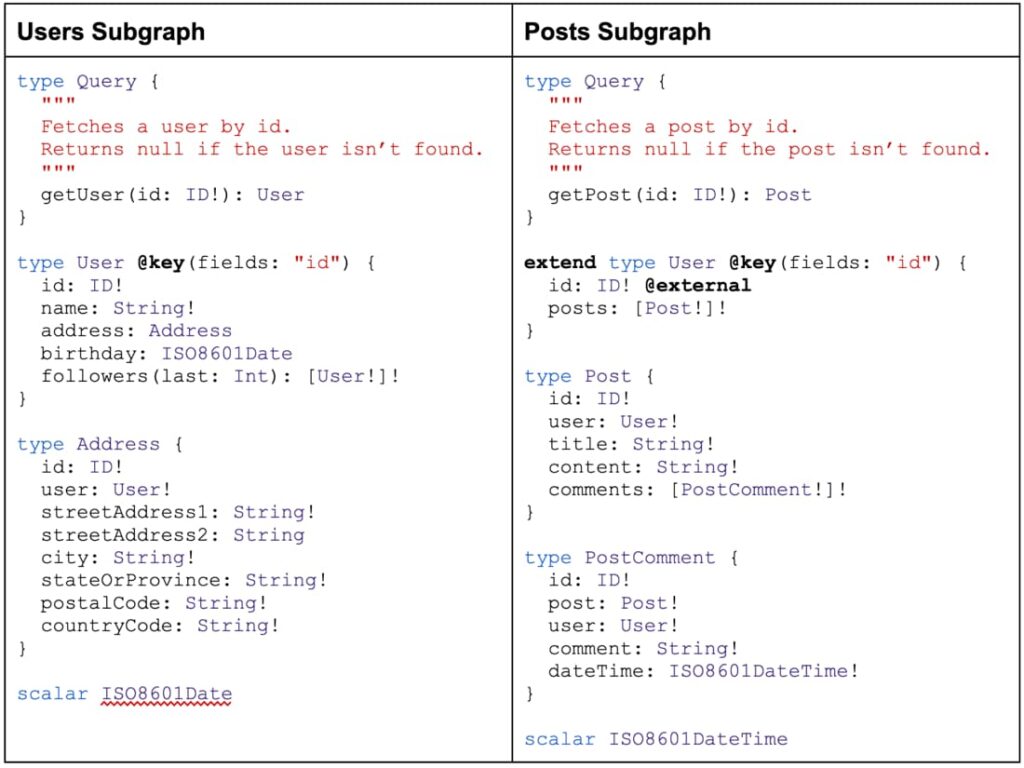
In this example, we’re splitting our microservices by domain – one microservice to handle user-specific data and another to handle post and post comment data. While the format is similar to our previous example, there are a few new concepts.
- In the Users Subgraph, you’ll see that the
Usertype now has a@key(fields: "id")attribute. The key directive indicates thatUservalues can be uniquely identified by the “id” value and enables the fetching of user records from external references. - The Posts Subgraph has a
Usertype as well. However, its version is simplified and contains only the user’s ID and a reference to the user’s posts. We’re using the extends keyword to extend the Users SubgraphUsertype to include theposts: [Post!]!attribute. - And finally, the external directive marks the Posts Subgraph’s
User.idattribute as owned by a separate service. The Posts Subgraph microservice will only need to supply theUser.idvalue. The supergraph gateway will query the Users Subgraph microservice to provide the remaining user data before returning the result to the web client.
This is advantageous because the developers working on the Posts microservice only have to store the user’s ID, the storage of the other user attributes isn’t duplicated, and the web client only needs to make one request.
Developer Thoughts
GraphQL offers a lot of value by reducing bandwidth requirements and speeding up web client requests. However, nothing is ever a silver bullet that will solve every problem, and GraphQL implementations can require a lot of planning. I don’t recommend running out and replacing your existing REST APIs with a GraphQL implementation.
That said, GraphQL is a great choice when you need to support different client views, have to be efficient with bandwidth and data storage, need to scale by concern, and want to combine multiple microservices into one endpoint seamlessly.
Benefits:
- Reduced bandwidth requirements – clients request only what’s needed
- Reduces or eliminates the need for separate Backend for Frontend supplemental applications
- Encourages separation of concerns
- Wide language support, as listed on the GraphQL Language Support page
- Open source and commercial support options are available
Drawbacks:
- Steep learning curve
- Requires additional planning when combining multiple services
- Complex and dynamic data structures are more challenging to cache
Conclusion
GraphQL provides functionality for defining an extensible and strong type-based schema to define the capabilities of an API. The schema is self-documenting and communicates to the user what to expect and how to use it. Requests and responses are validated to ensure that the action, requested data, and returned data match what’s available in the schema. Users specify the exact objects and fields needed from the entry points and only that data is returned.
Multiple GraphQL services can be combined and served from a single URL through various techniques. We briefly covered how this would work using an Apollo Federation (federation) distributed GraphQL architecture.
I’ve only scratched the surface of what GraphQL can provide and how it works. However, you should have a basic idea of what GraphQL is and how it compares to a REST API.

About Mission Data:
We’re designers, engineers, and strategists building innovative digital products that transform the way companies do business. Learn more: https://www.missiondata.com.

